I’m quite reassured by both talks at BigDataLDN and other talks at Skillsmatter (RIP) which have been across many different technologies, and the reoccurring theme is building a data warehouse.
Now a few years ago everyone declared the DWH was dead. Well that couldn’t be further from the truth. It did fall poorly for some time, but it seems to me to have got a second wind. It’s just virtualised now, but the modelling and concepts are more important than ever.
So; How do you maintain your dimensions? In a dimension record, your data can be versioned and you can choose whether you keep a history of your attributes (type2) or just overwrite with the latest value (type 1). There’s all sorts of combinations and variants of these too.
Now, Kettle or PDI (An industry standard Opensource ETL tool) has a lovely step which does ALL of this for you. So, I can maintain a dimension with just two steps. It’s also incredibly rich, so i can choose on a field by field basis exactly what i want to happen. Here’s a picture:
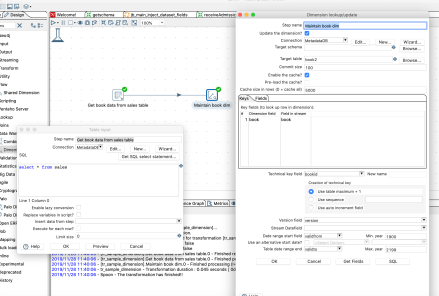
So, you can see here a table input, which runs a simple bit of SQL. And a lookup/update step which has about 5 fields of configuration, and boom! We have a fully maintained and updated dimension. Now rinse and repeat. Even a new user to Kettle could create this in 5-10 minutes.
Oh; And this is gloriously database independent too. Doesn’t matter what the DB is, source or target, it’ll work. Perhaps your SQL may occasionally need to be tweaked, but nothing in Kettle would change.
And also, while i’m at it (this is NOT a sales pitch btw!) Kettle will also generate the SQL for the target tables. And it’ll insert a zero record for the case when you can’t find the dimension. (A quirk about dimensional modelling that you must ALWAYS have a key in the fact table)
Now these days, where it’s at is python. Not ETL tools. OK so how do we do this in Python? Well actually, it’s also extremely simple. This time it took me about half an hour to get it working, but that is more reflective of my python knowledge than the tool itself. So how does it work? Lets work through the code line by line:
The first thing, is install the library “pygrametl” via pip. This seems to be a mature library, still occasionally updated, so seems a good one to use.
Then, in our code:

So that’s the usual imports, etc, fine, boring..
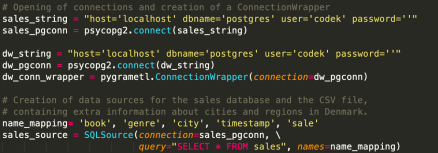
This is quite nice, here we’re defining two connections to postgres, and running some SQL. We’re also defining the mapping of the columns – something you don’t need to do in Kettle. Nevertheless with just a couple of lines we have our connection and we’ve ran our SQL. Good stuff.
Now lets define the dimension itself:

So there’s two here. The first one is type 1 (overwrite). The second is type 2 – update. (History) . So that’s also pretty simple, we’re just defining the fields and their uses. Good stuff. In fact you could actually generate this from metadata… Ooh..
Next, let’s update the dimension!
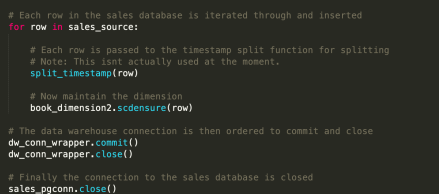
Again, that’s gloriously simple. For each row in the data, we simply make one call to our library to “ensure” the dimension. This then does either insert, update, or nothing. (And then don’t forget to close our connections!)
Done!
So, now what? All of this is great, but there’s one niggling problem here – Both tools rely on the data being in a relational database – or more specifically one that supports update functions. Athena (and other bigdata SQL engines on Hadoop) typically don’t support update so this doesn’t work.
That means you can either rebuild your whole dimension each time using inserts, or find another way. And if you’re going to do that, you need to have all the data to do so – sometimes the source doesn’t actually have this data, and it’s data you’ve curated, so be sure to read the dimension first in that case, before clearing it down!
So one way i’ve seen, is to abuse SQL to look forwards (or backwards) over the data and replicate the valid from / valid to and version fields in a View. Whilst this is really nice, as it hugely simplifies the stored data, it puts an awful lot of trust in the database being happy to run some more complex SQL.
So I think that leaves a hybrid – This is actually common in data architecture, and basically the advice is – use the right tool for the job. So in a hybrid setup your golden source of dimensional data is kept and maintained in an RDBMS, but then blatted over (Technical term sorry) to S3 or HDFS post updates. Again, in Kettle this is something that is embarrassingly easy! (And probably in python too)
Any other thoughts? How do you manage your dimensions when your DWH is based upon a filestore rather than an RDBMS?
