Hmm, what what? Serverless PDI?
Yes, so serverless is *the* thing at the moment. Partly driven by amazing advances in the devops space – Fundamentally we’ve all had enough of managing servers, patching etc. You know the story.
“Run code not computers”
Why to do this? – Simple – Integration. If you need to hook up 2 APIs of separate systems it’s actually pretty expensive to have a server sitting there running 24×7. So what we want is to literally pay for the time we use and nothing more – We don’t want to have to startup and shutdown a whole server either!
Why Pentaho? The single most important argument is visual programming. It’s faster to get started with PDI than it is with a scripted solution. It’s more maintainable and it allows you to capitalise on general ETL skills. (Experience of any ETL tool is enough to work with PDI) . PDI has also done the boring input/output/API stuff, so all you need to focus on is your business logic. Simple!
So, how to do this? Well Amazon AWS Lambda is where to start. I assume google cloud has a similar function, but I’ve already got stuff running in AWS so this was a no brainer.
The stats sound good. Upload your app and you only pay for run time, everything else is handled. There’s even something called API connect so you can trigger your ‘Functions’. And finally – My favourite automation service Skeddly can also trigger AWS Lambda functions. Great!
There is one issue. The jar has to be less than 100mb. What! PDI is 1GB, how can that possibly make sense. Sure enough some googling shows lots of other people trying to use PDI in lamdba and finding this limit is far too low.
But; Matt Casters pointed out to me the kettle engine is only 6mb. What? Really? I took a look – and sure enough with a few dependencies thrown in you can build a PDI engine archive which only uses 22MB. We’re on.
To start, read these two pages:
Then:
- Create a pom.xml
- Add in your example java code
- Build the jar (mvn package).
- Remove any signed files: cd target; zip -d <file>.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF
- Upload as a lambda function
- Set an environment variable KETTLE_HOME=/tmp (If you dont PDI will crash as the default home dir in lambda isn’t writable)
- TEST!
And here’s the proof:
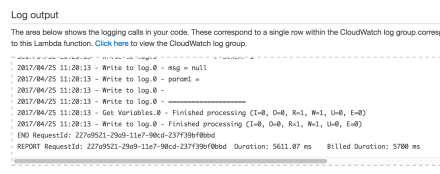
Slightly disconcerting that it took 5.7s to run. On my laptop the same executed in 0.5s. I guess the lambda physical boxes are busy and low spec!
What’s next?
- Find a better way to package the ktr
- Hook the input file into PDI parameters
- Provide better output than “Done”!
- Setup with the API connect
- Schedule via Skeddly
I will be releasing all the code for this soon – In the mean time if anyone is particularly interested in this right now please do contact me. I think it’s a very interesting area and this simple integration opens up a vast amount of power.
